Recently a brand new command was released that could help you scan for PII (Personal Identifiable Information) in our databases.
What Is Personally Identifiable Information (PII)?
Personally identifiable information (PII) is like the name implies, data that can be used to identify a person. It is typically actively collected, meaning the information is provided directly by the individual. Here are a couple of identifiers that qualify as PII-based data:
- Name
- Email address
- Postal address
- Phone number
- Personal ID numbers (e.g., social security, passport, driver’s license, bank account)
Why is this command developed
The idea came from a line of commands that are present in dbatools to mask data. Although these commands are great, going through all of the tables and looking through the data was a bit tedious for me. Especially when you’re dealing with databases that have hundreds to thousands of tables, you easily run into the thousands to tens of thousands of columns. So that’s how I came up with the command to scan for PII and it’s called Invoke-DbaDbPiiScan and is present in dbatools from version 0.9.819. The command returns all the columns that potentially contain PII. I must say potentially because the results still need to be assessed if it indeed contains PII. But it takes care of eliminating the majority of the columns saving you a lot of time. This information is very valuable when you have to deal with the GDPR, but also when you have to deal with things like HIPAA.
How does the command work work
It’s set up in such a way that to improve the scan, we only need to look at the known name and the patterns. The known names and patterns are set up using regex or regular expressions in full.
Regular Expressions are a sequence of characters that defines a search pattern. It can be used to match a series of characters from simple to very complex.
The files with the regular expressions are located in the bin\datamasking folder. During the scan the command will go through two phases:
- Scan for known names
- Scan for data patterns
If the command comes across a column that matches phase one, it will skip that column for phase 2. Because it already flagged this column to potentially have PII, it would not make sense to also try to match all the patterns on it. Avoiding this makes the process fast and efficient.
Known Names
The file that contains all the known column names is called pii-knownnames.json. A known name has the following properties:
- Name
- Category
- Pattern
An example of a known name is:
{
"Name": "Name",
"Category": "Personal",
"Pattern": \["^.\*(firstname|fname|lastname|lname|fullname|fname).\*$"\]
}
In this example, if the name of the column matches anything like firstname, fname, lastname, etc, it will return in the scan.
Data Patterns
The file that contains all the data patterns is called pii-patterns.json. A pattern has the following properties:
- Name
- Category
- Country
- CountryCode
- Pattern
- Description (not yet in production at the time of writing this article)
The pattern has a little more information than the known name. The reason for that is that the known name is not bound to countries and only applies to language. Because a language can be used in multiple countries, adding a country to the known name wouldn’t make sense. The second reason why there is a country and countrycode property is that this enables the user to filter on specific countries. Imagine you have a database with only data from a specific country, going through a very large set of patterns would be a very long process. With the country and country code, the command can filter on the patterns and only try to match those that make sense for the user. An example of a pattern is:
{
"Name": "Creditcard Mastercard",
"Category": "Financial",
"Country": "All",
"CountryCode": "All",
"Pattern": "(5\[1-5\]\\\\d{14})|(5\[1-5\]\\\\d{2}\[-| \]\\\\d{4}\[-| \]\\\\d{4}\[-| \]\\\\d{4})",
"Description": ""
}
Running the command
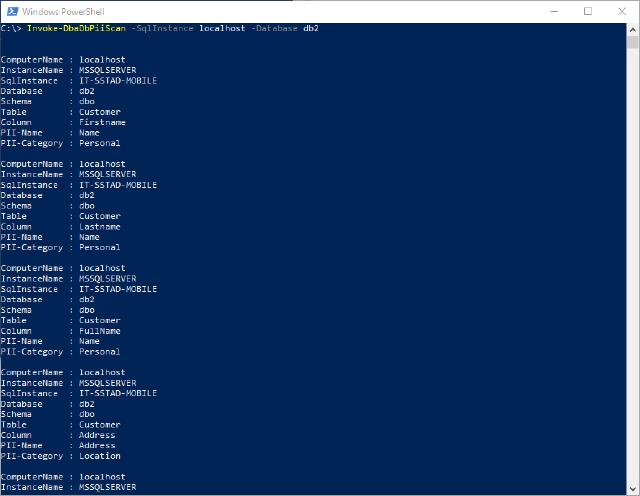
Enough to talk about how it all works, let’s get to the point to execute the command. The easiest way of running the command is by executing the following line (replacing the brackets of course)
Invoke-DbaDbPiiScan -SqlInstance [yourserver] -Database [yourdatabase]
The result would look something like this
Invoke-DbaDbPiiScan -SqlInstance [yourserver] -Database [yourdatabase] | Out-GridView
The result would look something like this
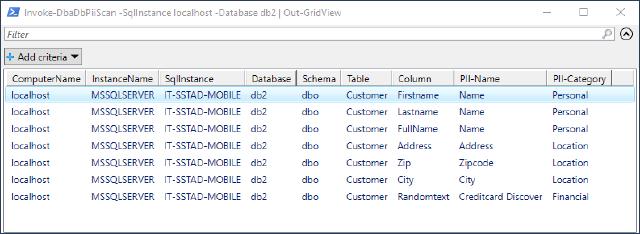
What’s next?
The next step with this command is to implement the functionality in the New-DbaDbDataMaskingConfig command. I want the user to be able to go straight to the usual suspects in the database and only create a config for those columns that potentially have PII. The command has several other parameters to make more specific scans. Take a look at the help from the command to get to know more about the other parameters.
Get-Help Invoke-DbaDbPiiScan
There are also several examples in the help that can also get you very far. I hope this helps you out a bit. Especially when you’re dealing with the entire GDPR jungle finding all the little pieces within your organization that holds PII. If you want to think you’re missing some patterns or know names please help us out. With all of you, we can make this scan thorough.